




If you are paying attention to the tech field and business you might have heard about "Web3" a lot. It's a newly evolved version of the web that we all are familiar with. I myself am fascinated by the technology and the concept of decentralized and distributed internet.
When you start exploring Web3, one of the first things you will hear about is IPFS. So what the hell is this IPFS? Hold your horse's buddy. Before getting into what IPFS is let's see how the current internet works and what the problem with it is.
Issues with the current Internet
As of January 2021, there are 4.66 billion active internet users worldwide which roughly equals 60 percent of the global population! The current internet is a centralized system, which means each node in the network is connected to a central node that controls the entire system. All the information on the internet is centralized since all data is kept in large server farms controlled by specific entities such as companies. This means that these entities are prone to censorship and it also creates a single point of failure. Say the servers of Youtube go down, how will you access it? Doesn't that mean it's a single point of failure?

It's not like the current internet has no benefits at all. The speed at which we are able to access information is the biggest advantage of the current internet. Accessing files, blogs, websites, or any other content is possible in a matter of seconds with a single click of a button.
Location-based addressing
The internet is dominated by client-server relationships, which rely on the Internet Protocol suite. Of these, Hypertext Transfer Protocol (HTTP) is the basis for communication. Data is stored in centralized servers and accessed by location-based addressing. This makes it easier to distribute, manage, secure the data, and to scale the capacity of both servers and clients.
"IPFS aims to surpass HTTP in order to build a better web for all of us."
In location-based addressing, data is identified by where it is located rather than its content. This limitation means you have to go all the way to a specific location to access a piece of data, even if that same data is available somewhere closer. There is also no way of telling if the data has been altered since the client only needs to know where it is, not what it is.
This means that when we ask our computers to fetch a file, we essentially provide the computer with the location where the content is, and in return, we are provided with that information. An example of a “location” in this context can be either an IP address or a domain. Say you googled for en.wikipedia.org/wiki/Main_Page, it's essentially the location where the data is stored.
Ownership of data
No one really cares about the monopolization of information by specific entities. But it does matter a lot. We really don't own our own data even though we should. Say you are browsing through Facebook or Instagram and liking and commenting on posts, you are inevitably creating data. Whether it’s your online activity, what you like and dislike, your buying habits, or a whole range of other sensitive information, it is almost worthless in isolation.
The data value arises when organizations use advanced analytics programs to help inform business decisions. If your data can help companies save or make money, then suddenly it becomes important.
Make no mistake, you are not the customer, you are the data generator.

Facebook and Instagram are literally designed to promote endless scrolling so that you reveal your likes and dislikes. Your data is one of the most valuable resources on the planet.
This is exactly the problem with the current web. Ownership of the data, its centralized. Everything changes if our internet was decentralized, where we own our data and actually get benefit from it.
In a decentralized world, you would own your data as an asset. If the data economy wants to continue, they will need to meet your personal data valuation. Essentially, each individual will be in charge of data monetization for themselves.
A decentralized solution to storing and accessing files comes in the form of the InterPlanetary File System or IPFS. To shift from the present version of the web to a distributed version of the web, we need IPFS. Essentially, the aim is to replace HTTP. Moreover, a decentralized network is a key prospect for the promise of Web3!
What is IPFS (InterPlanetary File System)?
Now back to our question, what the hell is this IPFS? IPFS, which stands for InterPlanetary File System, began development in 2015 by the company Protocol Labs. Back in its early days, the team working on IPFS was a small team of developers led by Juan Benet, CEO of the company. IPFS was initially designed to be a P2P (peer-to-peer)-based decentralized solution for storing and accessing files.
IPFS is a distributed system for storing and accessing files, websites, applications, and data designed to make the web faster, safer, and more open
Fast forward to today, IPFS can be described as a decentralized protocol for storing content – including data, websites, files, and applications – as well as accessing this data in a decentralized way. IPFS eliminates the problems of censorship and a single point of failure. So, now you may ask how does this solution different from our current centralized Internet?
Content-based addressing
As mentioned earlier, the current web retrieves data from a location that we mentioned. IPFS on the other hand utilizes content-based addressing. This essentially means the content is located based on the content itself rather than the location of the content.
An HTTP request (location-based addressing) would look like http://1.2.3.4/main/mypic.png
An IPFS request (content-based addressing) would look like /ipfs/QxmT42vH7/main/mypic.png
So instead of telling the computer where the content is located, IPFS lets us request the content based on the content itself. Amazing right? But there is one problem, the computer must know how to find a specific file.
For content-based addressing to work, there must be a working system to uniquely identify the content. And that is done by assigning a unique ID to the content called a hash. Since each hash is entirely unique to the content it represents, it is possible for the computer to find the content based on the hash.
A request to retrieve data from the web must provide the content identifier, from which the system can determine the physical location of the content and retrieve it. One thing to note here is that since the identifier is created based on the content, any change in content ideally changes the identifier itself, i.e the content address itself.
Content-based addressing and utilizing hashes is not something that IPFS introduced, as other systems use the same methods.
The InterPlanetary Name System (IPNS)
As we have discussed, IPFS uses content-based addressing. It creates an address of a file based on data contained within the file. If you were to share an IPFS address such as /ipfs/QmbezGequPwcsWo8UL4wDF6a8hYwM1hmbzYv2mnKkEWaUp with someone, you would need to give the person a new link every time you update the content.
The InterPlanetary Name System (IPNS) solves this issue by creating an address that can be updated.
A name in IPNS is the hash of a public key. The owner of the public key can sign a piece of information containing the IPNS hash linking to the most recent version of the content. New records can be signed and published at any time.
That means that if I shared the IPNS hash, I could direct users to the same website and it would still allow me to make updates.
There is one drawback though, IPNS hashes are not human-readable as you can see. This issue is actually solved by ENS. Ethereum Name Service (ENS), is a protocol for human-readable crypto addresses and decentralized domain names. We can discuss more in a later article.
Directed Acyclic Graphs (DAGs)
Directed Acyclic Graphs (DAGs) are a form of data structure utilized by various distributed systems. IPFS specifically utilizes DAGs structures known as Merkle DAGs. In this data structure, each node has a unique hash representing the content of that specific node. This means that identifying an object or a node by the value of that node’s hash is possible, which is what content-based addressing is.
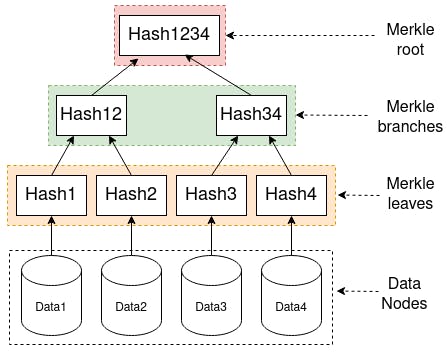
There are different ways in which we can construct a Merkle DAG, but IPFS structure is optimized to follow a file system (as the name says!). This means that the system splits the content into different blocks for the IPFS protocol to create a DAG representation of the content. This structure forms a Merkle DAG graph since each file has a content ID, files in the same folder have their own content IDs and the folder itself has a content ID. So many content IDs, I know XD.
Another beneficial effect of using this data structure is that similar files can share parts of the Merkle DAG. This means that if we update any project, only the updated files will receive a new content ID. This also means that the old and new versions can refer to the same blocks for all unaltered parts!
IPFS is an interesting solution for storing files on the web and will most likely be an important protocol for Web3.
How does IPFS store the data?
Now we do have a basic understanding of what IPFS is and how content-based addressing comes into the picture. However, we still haven't learned how IPFS stores the data.
IPFS Objects
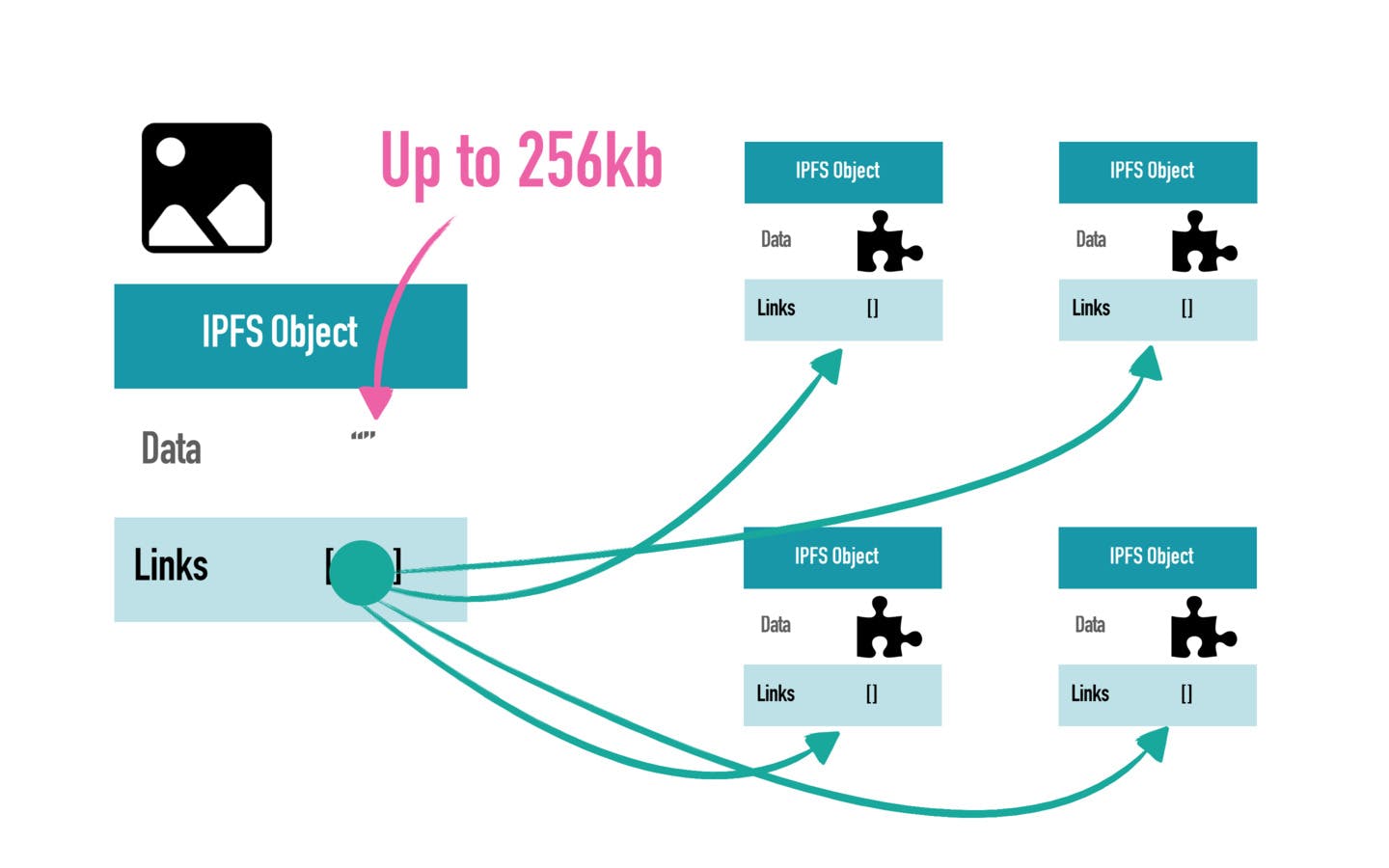
When storing files in IPFS, the system creates an IPFS object. These objects can store up to 256KBs worth of data. They can also contain links to other IPFS objects. Now you may wonder how it stores larger files like an image or video.
Those are actually split up into multiple IPFS objects of the size 256KB and afterward, the system will create another IPFS object that holds the links to all the pieces of the files. It's a straightforward simple yet powerful architecture.
Versioning in IPFS
The IPFS objects are actually immutable objects. Then how do we change stuffs you ask? That's where versioning comes into the picture. IPFS supports the versioning of the files. If you happen to be working on a file, IPFS will create what they call a commit object for you.
The commit object simply refers to the commit that came prior to that one and then links to the latest version of the file. All these different versions of a specific file are then available to the nodes of the system. IPFS will make sure that your files, plus their entire history is accessible to the other nodes in the network.
Further information on how IPFS stores data can be found in the official documentation on their website.
Is there any catch?
Yes, there is a catch. If the nodes that hold these pieces of files are offline then the file becomes unavailable and no one can grab a copy of it. It will be like BitTorrent swarms without seeders. There are actually two solutions to this problem, either we can incentivize the nodes or proactively distribute the files and makes sure there is a certain number of copies always available. This is exactly what Filecoin intends to do. It is again a project of Protocol Labs.
How does IPFS locate the data?
You may now wonder how the system locates the data. That is essentially solved by the Distributed Hash Tables. A hash table is a data structure that stores information as key/value pairs. In distributed hash tables (DHT) the data is spread across a network of computers, and efficiently coordinated to enable efficient access and lookup between nodes.
The main advantages of DHTs are decentralization, fault tolerance, and scalability. Nodes do not require central coordination, the system can function reliably even when nodes fail or leave the network, and DHTs can scale to accommodate millions of nodes. Together these features result in a system that is generally more resilient than client-server structures.
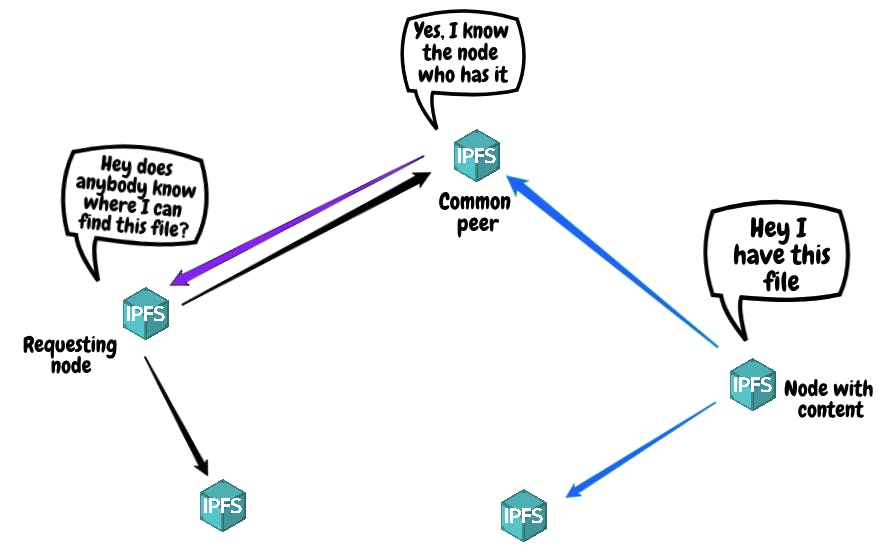
The fact that the hash table is distributed means that it is split across all the nodes in the network. Then to locate the content you are after, you ask the peers in the system. IPFS has something they call the ”libp2p project”, which provides DHTs and enables the peers in the system to communicate with each other. Once the content is located, which happens by finding out which peers in the system host the blocks that make up a file, then the next step is to find out where these peers are located. This means that the system uses the DHT twice in the process of locating the desired content.
As soon as the process of locating the content and the peers are done, an exchange needs to occur. When requesting or sending a block, IPFS uses something called Bitswap. This is what enables the peers in the network to connect with each other and to send the requested content. Once the content arrives, you are able to compare the content ID of the requested block and the one you have received to determine that it is the correct file.
Conclusion
Now as this article came to an end now you have a basic understanding of what an IPFS is, what content-based addressing is, how it stores data and how it locates the data.
Let's summarize :
- IPFS is a distributed system for accessing and storing files.
- IPFS uses a content-based addressing system.
- IPFS uses a Merkle DAG that is optimized for representing directories and files
- IPFS have IPNS which acts as a DNS in a decentralized world.
- IPFS stores data as an immutable object called IPFS object and supports versioning of the files.
- IPFS locates the peer that hosts the data using Distributed hash tables (DHTs)
IPFS is pretty cool, right?
There are some advanced concepts in IPFS called Block exchanges, IPLD (Interplanetary Linked Data Project). We can discuss those in a later article.
That's it for today folks!! Thanks for reading this long article. I hope it was a great read for you and you learned one or two from it. If you have any doubts ask them away in the comments.
If you have any feedback please share it in the comment below. Also, if you find it helpful, please like and hit the follow button on the right top corner. Subscribe to my newsletter if you don't wanna miss any content.
Let's be friends at Twitter